

 中文
中文本地训练使用教程
没有任何的开发基础请慎重使用,出现问题请自行解决!
配置好本地训练的环境之后,就可以开始进行本地训练了,如果没有配置好的,请看上一篇教程
安装依赖
打开解压后得到的文件夹,打开里面的 requirements.txt 文件,将里面的 tensorflow>=2.3.1 删除,保存关闭。

在文件夹的这里输入cmd, 回车,进入命令行界面

输入
pip install -r requirements.txt
如果下载速度很慢的话,可以使用中科大源来进行下载
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
等待全部包的安装结束就可以了
数据集的制作
对于数据集的制作,请严格按照 Maixhub 上的数据集制作要求来进行。如果是分类训练可以不用进行压缩,但是要按压缩包的文件层级要求来将文件放到文件夹中
注意:对于压缩包中的文件夹名字和层级数一定要和要求中的一摸一样!一摸一样!不然会出现数据集读取不到等的一些奇奇怪怪的错误,导致训练不能开始。
开始训练
先进行初始化
python train.py init
开始训练之前,我们需要将自己本地训练的参数进行修改,在instance/config.py中进行修改对应的参数,否则就会出现错误,再进行训练
将数据集放到本地训练源码中的datasets文件夹中,然后在有train.py文件层级上启动命令行界面,和安装依赖的时的启动方法一样。
小白不知道怎么改的可以不用去修改

分类训练输入
python train.py -t classifier -z datasets/test_classifier_datasets.zip train
如果是没有压缩的文件夹,则输入
python train.py -t classifier -d datasets/test_classifier_datasets train
这里输入的命令中,在datasets/后面加的是你自己的所制作的数据集名字,不要上来就直接将复制命令运行。
目标检测输入
python train.py -t detector -z datasets/test_detector_xml_format.zip train
这里输入的命令中,在datasets/后面加的是你自己的所制作的数据集名字,不要上来就直接将复制命令运行。
训练完之后就会得到一个out的文件夹,里面的文件就是训练之后得到的模型
常见问题
训练过程中判断是否使用 GPU
启动训练的查看是否出现答应出这些信息,并都是和下图框出来的一样的
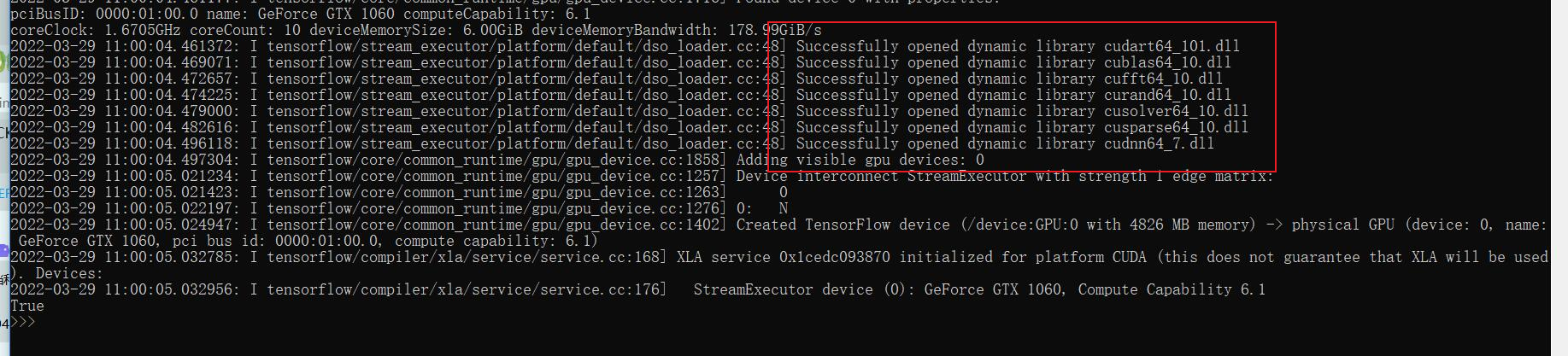
如果没有,则说明你的前面的cuda和cudnn环境没有安装好,请将所有关于英伟达的软件驱动进行卸载,是卸载!!!不是将文件删除。然后再重新进行cuda和cudnn的环境配置。在任务管理器中查看,GPU 的显存有没有被使用到,而不是看显卡的利用率
训练刚开始出现的 no GPU,will use CPU 只是一个提示信息而已,并不是没有使用到
训练中出现Internal: no kernel image is available for execution on the device
环境需要重新安装,tensorflow安装版本没有对上
出现failed: TrainFailReason.ERROR_PARAM, datasets not valid: datasets format error: datasets error, not support format, please check
这种就是没有严格的安装数据集要求来进行制作,检查你的文件夹名字,就可以解决的了,特别是images这个文件夹,容易少了个s
