
 中文
中文为 MaixCAM MaixPy 离线训练 YOLO26/YOLO11/YOLOv8 模型,自定义检测物体、关键点检测
更新历史
| 日期 | 版本 | 作者 | 更新内容 |
|---|---|---|---|
| 2026-02-04 | v4.0 | Tao | 增加 YOLO26 支持 |
| 2025-07-01 | v3.0 | neucrack | 增加 MaixCAM2 支持 |
| 2024-10-10 | v2.0 | neucrack | 增加 YOLO11 支持 |
| 2024-06-21 | v1.0 | neucrack | 编写文档 |
简介
默认官方提供了 80 种物体检测,如果不满足你的需求,可以自己训练检测的物体,可以在自己的电脑或者服务器搭建训练环境训练。
YOLOv8 / YOLO11 不光支持检测物体,还有 yolov8-pose / YOLO11-pose 支持关键点检测,出了官方的人体关键点,你还可以制作你自己的关键点数据集来训练检测指定的物体和关键点
因为 YOLOv8 和 YOLO11 主要是修改了内部网络,预处理和后处理都是一样的,所以 YOLOv8 和 YOLO11 的训练转换步骤相同,只是输出节点的名称不一样。
注意: 本文讲了如何自定义训练,但是有一些基础知识默认你已经拥有,如果没有请自行学习:
- 本文不会讲解如何安装训练环境,请自行搜索安装(Pytorch 环境安装)测试。
- 本文不会讲解机器学习的基本概念、linux相关基础使用知识。
如果你觉得本文哪里需要改进,欢迎点击右上角编辑本文贡献并提交 文档 PR。
流程和本文目标
要想我们的模型能在 MaixPy (MaixCAM)上使用,需要经历以下过程:
- 搭建训练环境,本文略过,请自行搜索 pytorch 训练环境搭建。
- 拉取 YOLO11/YOLOv8/YOLO26 源码到本地。
- 准备数据集,并做成 YOLO11 / YOLOv8 /YOLO26 项目需要的格式。
- 训练模型,得到一个
onnx模型文件,也是本文的最终输出文件。 - 将
onnx模型转换成 MaixPy 支持的MUD文件,这个过程在模型转换文章中有详细介绍: - 使用 MaixPy 加载模型运行。
哪里找数据集训练
请看哪里找数据集
参考文章
因为是比较通用的操作过程,本文只给一个流程介绍,具体细节可以自行看 YOLO26 / YOLO11 / YOLOv8 官方代码和文档(推荐),以及搜索其训练教程,最终导出 onnx 文件即可。
如果你有觉得讲得不错的文章欢迎修改本文并提交 PR。
YOLO26 / YOLO11 / YOLOv8 导出 onnx 模型
在 ultralytics 目录下创建一个export_onnx.py 文件
from ultralytics import YOLO
import sys
print(sys.path)
net_name = sys.argv[1] # yolov8n.pt yolov8n-pose.pt # https://docs.ultralytics.com/models/yolov8/#supported-tasks-and-modes
input_width = int(sys.argv[2])
input_height = int(sys.argv[3])
# Load a model
model = YOLO(net_name) # load an official model
# model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
path = model.export(format="onnx", imgsz=[input_height, input_width], dynamic=False, simplify=True, opset=17) # export the model to ONNX format
print(path)
然后执行python export_onnx.py yolov8n.pt 320 224 就能导出 onnx 模型了,这里重新指定了输入分辨率,模型训练的时候用的640x640,我们重新指定了分辨率方便提升运行速度,这里使用320x224的原因是和 MaixCAM 的屏幕比例比较相近方便显示,对于 MaixCAM2 可以用 640x480或者 320x240,具体可以根据你的需求设置就好了。
转换为 MaixCAM 支持的模型以及 mud 文件
MaixPy/MaixCDK 目前支持了 YOLO26 / YOLOv8 / YOLO11 检测 以及 YOLOv8-pose / YOLO11-pose 关键点检测 以及 YOLOv8-seg / YOLO11-seg YOLOv8-obb / YOLOV11-obb 四种模型(2026.2.4)。
按照MaixCAM 模型转换 和 MaixCAM2 模型转换 进行模型转换。
输出节点选择
注意模型输出节点的选择(注意可能你的模型可能数值不完全一样,看下面的图找到相同的节点即可):
对于 YOLO11 / YOLOv8, MaixPy 支持了两种节点选择,可以根据硬件平台适当选择:
| 模型和特点 | 方案一 | 方案二 |
|---|---|---|
| 适用设备 | MaixCAM2(推荐) MaixCAM(速度比方案二慢一点点) |
MaixCAM(推荐) |
| 特点 | 将更多的计算给 CPU 后处理,量化更不容易出问题,速度略微慢于方案二 | 将更多的计算给 NPU 并且参与量化 |
| 注意点 | 无 | MaixCAM2 实测量化失败 |
| 检测 YOLOv8 | /model.22/Concat_1_output_0/model.22/Concat_2_output_0/model.22/Concat_3_output_0 |
/model.22/dfl/conv/Conv_output_0/model.22/Sigmoid_output_0 |
| 检测 YOLO11 | /model.23/Concat_output_0/model.23/Concat_1_output_0/model.23/Concat_2_output_0 |
/model.23/dfl/conv/Conv_output_0/model.23/Sigmoid_output_0 |
| 关键点 YOLOv8-pose | /model.22/Concat_1_output_0/model.22/Concat_2_output_0/model.22/Concat_3_output_0/model.22/Concat_output_0 |
/model.22/dfl/conv/Conv_output_0/model.22/Sigmoid_output_0/model.22/Concat_output_0 |
| 关键点 YOLO11-pose | /model.23/Concat_1_output_0/model.23/Concat_2_output_0/model.23/Concat_3_output_0/model.23/Concat_output_0 |
/model.23/dfl/conv/Conv_output_0/model.23/Sigmoid_output_0/model.23/Concat_output_0 |
| 分割 YOLOv8-seg | /model.22/Concat_1_output_0/model.22/Concat_2_output_0/model.22/Concat_3_output_0/model.22/Concat_output_0output1 |
/model.22/dfl/conv/Conv_output_0/model.22/Sigmoid_output_0/model.22/Concat_output_0output1 |
| 分割 YOLO11-seg | /model.23/Concat_1_output_0/model.23/Concat_2_output_0/model.23/Concat_3_output_0/model.23/Concat_output_0output1 |
/model.23/dfl/conv/Conv_output_0/model.23/Sigmoid_output_0/model.23/Concat_output_0output1 |
| 旋转框 YOLOv8-obb | /model.22/Concat_1_output_0/model.22/Concat_2_output_0/model.22/Concat_3_output_0/model.22/Concat_output_0 |
/model.22/dfl/conv/Conv_output_0/model.22/Sigmoid_1_output_0/model.22/Sigmoid_output_0 |
| 旋转框 YOLO11-obb | /model.23/Concat_1_output_0/model.23/Concat_2_output_0/model.23/Concat_3_output_0/model.23/Concat_output_0 |
/model.23/dfl/conv/Conv_output_0/model.23/Sigmoid_1_output_0/model.23/Sigmoid_output_0 |
| 检测 YOLO26 | /model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0 /model.23/one2one_cv2.1/one2one_cv2.1.2/Conv_output_0 /model.23/one2one_cv2.2/one2one_cv2.2.2/Conv_output_0 /model.23/one2one_cv3.0/one2one_cv3.0.2/Conv_output_0 /model.23/one2one_cv3.1/one2one_cv3.1.2/Conv_output_0 /model.23/one2one_cv3.2/one2one_cv3.2.2/Conv_output_0 |
同MaixCAM2 |
| YOLOv8/YOLO11 检测输出节点图 | 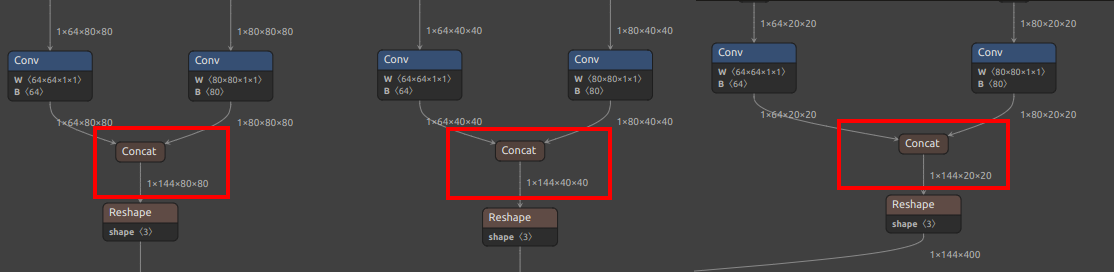 |
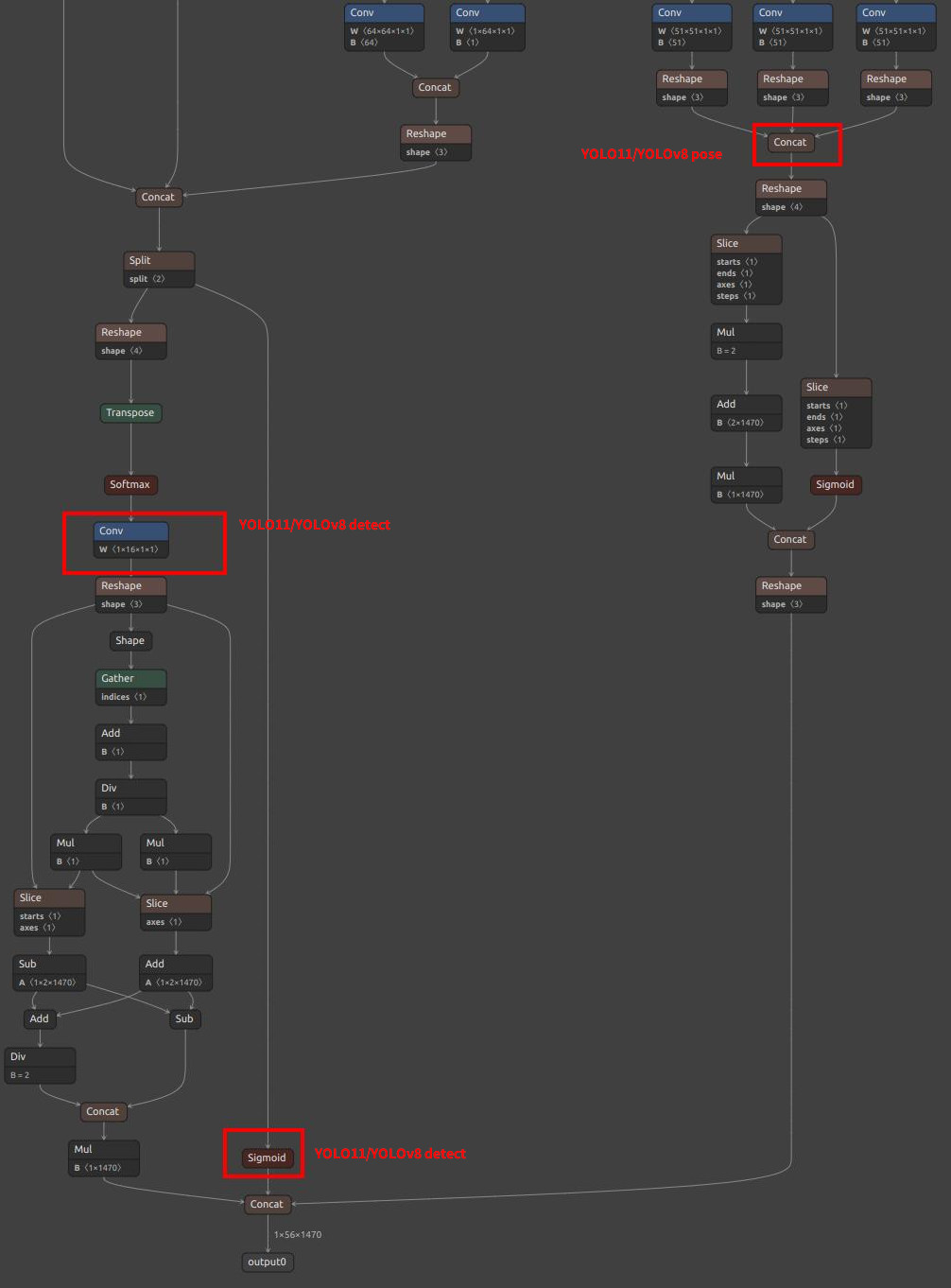 |
| YOLOv8/YOLO11 pose 额外输出节点 | 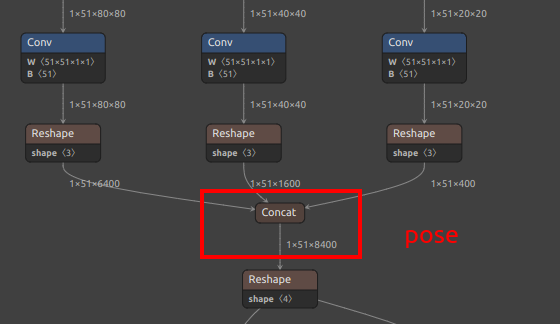 |
见上图 pose 分支 |
| YOLOv8/YOLO11 seg 额外输出节点 | 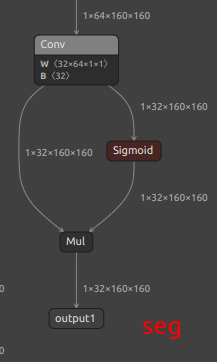 |
|
| YOLOv8/YOLO11 OBB 额外输出节点 | 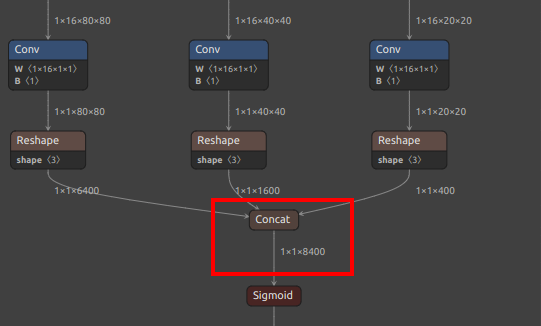 |
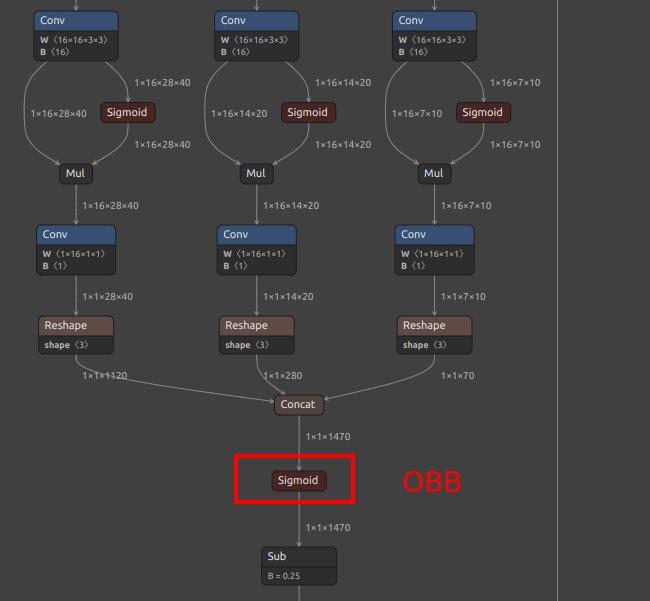 |
| 检测 YOLO26 输出节点图 | 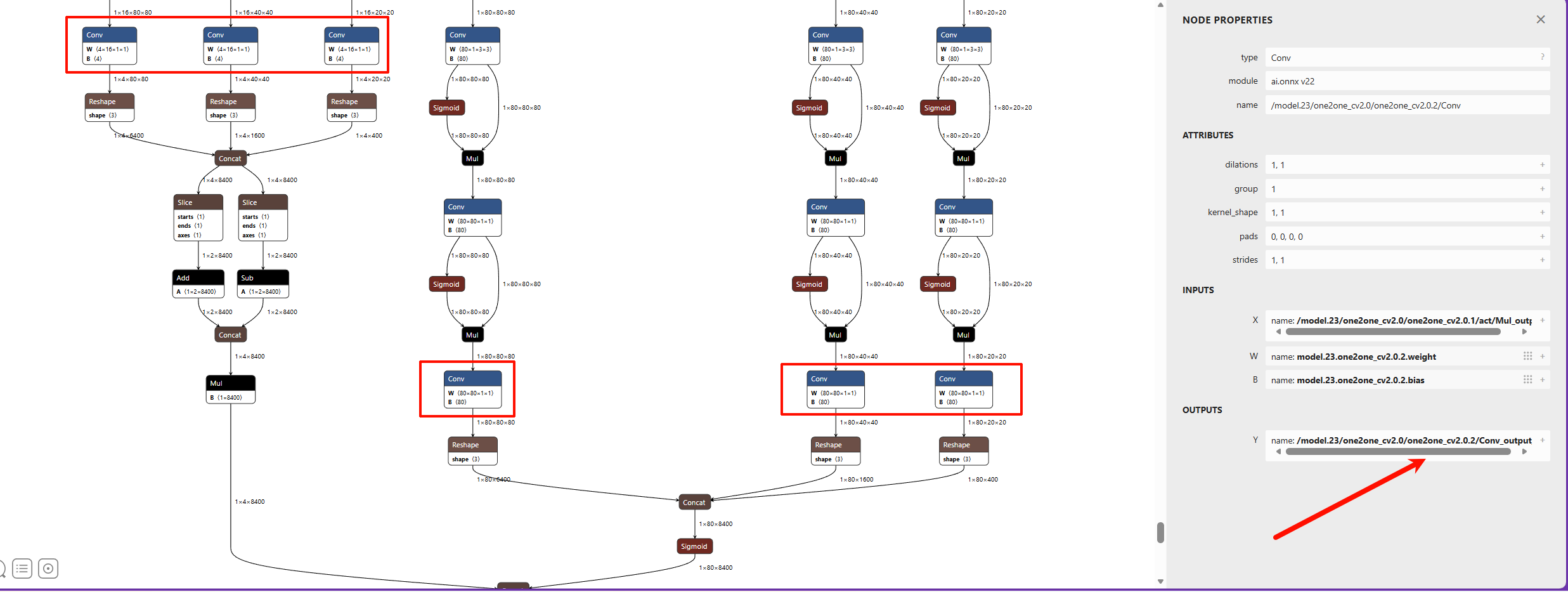 |
同MaixCAM2 |
转换脚本
这里提供一键转换YOLO26的脚本(需要在容器下运行):
MaixCam/Pro:
#!/bin/bash
set -e
net_name=yolo26n
input_w=320
input_h=224
# mean: 0, 0, 0
# std: 255, 255, 255
# mean
# 1/std
# mean: 0, 0, 0
# scale: 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
# convert to mlir
model_transform.py \
--model_name ${net_name} \
--model_def ./${net_name}.onnx \
--input_shapes [[1,3,${input_h},${input_w}]] \
--mean "0,0,0" \
--scale "0.00392156862745098,0.00392156862745098,0.00392156862745098" \
--keep_aspect_ratio \
--pixel_format rgb \
--channel_format nchw \
--output_names "/model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0,/model.23/one2one_cv2.1/one2one_cv2.1.2/Conv_output_0,/model.23/one2one_cv2.2/one2one_cv2.2.2/Conv_output_0,/model.23/one2one_cv3.0/one2one_cv3.0.2/Conv_output_0,/model.23/one2one_cv3.1/one2one_cv3.1.2/Conv_output_0,/model.23/one2one_cv3.2/one2one_cv3.2.2/Conv_output_0" \
--test_input ./image.jpg \
--test_result ${net_name}_top_outputs.npz \
--tolerance 0.99,0.99 \
--mlir ${net_name}.mlir
echo "calibrate for int8 model"
# export int8 model
run_calibration.py ${net_name}.mlir \
--dataset ./coco \
--input_num 200 \
-o ${net_name}_cali_table
echo "convert to int8 model"
# export int8 model
# add --quant_input, use int8 for faster processing in maix.nn.NN.forward_image
model_deploy.py \
--mlir ${net_name}.mlir \
--quantize INT8 \
--quant_input \
--calibration_table ${net_name}_cali_table \
--processor cv181x \
--test_input ${net_name}_in_f32.npz \
--test_reference ${net_name}_top_outputs.npz \
--tolerance 0.9,0.6 \
--model ${net_name}_int8.cvimodel
MaixCam2:
#!/bin/bash
set -e
############# 修改 ####################
model_name=$1
model_path=./${model_name}.onnx
images_dir=./coco
images_num=100
input_names=images
config_path=yolo26_build_config.json
output_nodes=(
"/model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0" # bbox 80x80
"/model.23/one2one_cv2.1/one2one_cv2.1.2/Conv_output_0" # bbox 40x40
"/model.23/one2one_cv2.2/one2one_cv2.2.2/Conv_output_0" # bbox 20x20
"/model.23/one2one_cv3.0/one2one_cv3.0.2/Conv_output_0" # cls 80x80
"/model.23/one2one_cv3.1/one2one_cv3.1.2/Conv_output_0" # cls 40x40
"/model.23/one2one_cv3.2/one2one_cv3.2.2/Conv_output_0" # cls 20x20
)
#############################################
# 解析节点配置
onnx_output_names=""
json_outputs=""
for node in "${output_nodes[@]}"; do
# 构建 extract_onnx 的输出参数
if [ -n "$onnx_output_names" ]; then
onnx_output_names="${onnx_output_names},"
fi
onnx_output_names="${onnx_output_names}${node}"
# 构建 JSON output_processors
json_outputs="${json_outputs}
{
\"tensor_name\": \"${node}\",
\"dst_perm\": [0, 2, 3, 1]
},"
done
# 去掉最后的逗号
json_outputs="${json_outputs%,}"
# 生成 JSON 配置文件
cat > $config_path << EOF
{
"model_type": "ONNX",
"npu_mode": "NPU1",
"quant": {
"input_configs": [
{
"tensor_name": "${input_names}",
"calibration_dataset": "tmp_images/images.tar",
"calibration_size": ${images_num},
"calibration_mean": [0, 0, 0],
"calibration_std": [255, 255, 255]
}
],
"calibration_method": "MinMax",
"precision_analysis": true
},
"input_processors": [
{
"tensor_name": "${input_names}",
"tensor_format": "RGB",
"tensor_layout": "NCHW",
"src_format": "RGB",
"src_dtype": "U8",
"src_layout": "NHWC",
"csc_mode": "NoCSC"
}
],
"output_processors": [${json_outputs}
],
"compiler": {
"check": 3,
"check_mode": "CheckOutput",
"check_cosine_simularity": 0.9
}
}
EOF
echo -e "\e[32m已生成配置文件: ${config_path}\e[0m"
# 创建 gen_cali_images_tar.py
cat > gen_cali_images_tar.py << 'PYTHON_SCRIPT'
import sys
import os
import random
import shutil
images_dir = sys.argv[1]
images_num = int(sys.argv[2])
print("images dir:", images_dir)
print("images num:", images_num)
print("current dir:", os.getcwd())
files = os.listdir(images_dir)
valid = []
for name in files:
path = os.path.join(images_dir, name)
ext = os.path.splitext(name)[1]
if ext.lower() not in [".jpg", ".jpeg", ".png"]:
continue
valid.append(path)
print(f"images dir {images_dir} have {len(valid)} images")
if len(valid) < images_num:
print(f"no enough images in {images_dir}, have: {len(valid)}, need {images_num}")
sys.exit(1)
idxes = random.sample(range(len(valid)), images_num)
shutil.rmtree("tmp_images", ignore_errors=True)
os.makedirs("tmp_images/images")
for i in idxes:
target = os.path.join("tmp_images", "images", os.path.basename(valid[i]))
shutil.copyfile(valid[i], target)
os.chdir("tmp_images/images")
os.system("tar -cf ../images.tar *")
# shutil.rmtree("tmp_images/images")
PYTHON_SCRIPT
# 创建 extract_onnx.py
cat > extract_onnx.py << 'PYTHON_SCRIPT'
import onnx
import sys
input_path = sys.argv[1]
output_path = sys.argv[2]
input_names_str = sys.argv[3]
output_names_str = sys.argv[4]
input_names = []
for s in input_names_str.split(","):
input_names.append(s.strip())
output_names = []
for s in output_names_str.split(","):
output_names.append(s.strip())
onnx.utils.extract_model(input_path, output_path, input_names, output_names)
PYTHON_SCRIPT
# extract and onnxsim
mkdir -p tmp1
onnx_extracted=tmp1/${model_name}_extracted.onnx
onnxsim_path=tmp1/${model_name}.onnx
# Step 1: 提取指定输出节点
echo -e "\e[32mStep 1: 提取 ONNX 输出节点\e[0m"
python extract_onnx.py $model_path $onnx_extracted $input_names "$onnx_output_names"
# Step 2: 简化模型
echo -e "\e[32mStep 2: ONNX 简化\e[0m"
onnxsim $onnx_extracted $onnxsim_path
python gen_cali_images_tar.py $images_dir $images_num
mkdir -p out
tmp_config_path=tmp/$config_path
# vnpu
echo -e "\e[32mBuilding ${model_name}_vnpu.axmodel\e[0m"
rm -rf tmp
mkdir tmp
cp $config_path $tmp_config_path
sed -i '/npu_mode/c\"npu_mode": "NPU1",' $tmp_config_path
pulsar2 build --target_hardware AX620E --input $onnxsim_path --output_dir tmp --config $tmp_config_path
cp tmp/compiled.axmodel out/${model_name}_vnpu.axmodel
# npu all
echo -e "\e[32mBuilding ${model_name}_npu.axmodel\e[0m"
rm -rf tmp
mkdir tmp
cp $config_path $tmp_config_path
sed -i '/npu_mode/c\"npu_mode": "NPU2",' $tmp_config_path
pulsar2 build --target_hardware AX620E --input $onnxsim_path --output_dir tmp --config $tmp_config_path
cp tmp/compiled.axmodel out/${model_name}_npu.axmodel
rm -rf tmp
echo -e "\e[32mGenerate models done, in out dir\e[0m"
修改 mud 文件
对于物体检测,mud 文件为(YOLO11 model_type 改为 yolo11 YOLO26 model_type 改为 yolo26)
MaixCAM/MaixCAM-Pro:
[basic]
type = cvimodel
model = yolov8n.cvimodel
[extra]
model_type = yolov8
input_type = rgb
mean = 0, 0, 0
scale = 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
labels = person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush
MaixCAM2:
[basic]
type = axmodel
model_npu = yolo11n_640x480_npu.axmodel
model_vnpu = yolo11n_640x480_vnpu.axmodel
[extra]
model_type = yolo11
type=detector
input_type = rgb
labels = person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush
input_cache = true
output_cache = true
input_cache_flush = false
output_cache_inval = true
mean = 0,0,0
scale = 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
根据你训练的对象替换labels即可。
对于关键点检测(yolov8-pose),修改 type=pose。
对于关键点检测(yolov8-seg),修改 type=seg。
对于关键点检测(yolov8-obb),修改 type=obb。
上传分享到 MaixHub
到 MaixHub 模型库 上传并分享你的模型,可以多提供几个分辨率供大家选择。
