
 English
EnglishOffline Training YOLO Models for MaixCAM MaixPy, Custom Object Detection and Keypoint Detection
Update history
| Date | Version | Author | Update content |
|---|---|---|---|
| 2026-02-04 | v4.0 | Tao | Added YOLO26 support |
| 2025-07-01 | v3.0 | neucrack | Added MaixCAM2 support |
| 2024-10-10 | v2.0 | neucrack | Added YOLO11 support |
| 2024-06-21 | v1.0 | neucrack | Initial documentation |
Introduction
By default, the official firmware provides detection for 80 object classes. If these do not meet your needs, you can train your own object detection model by setting up a training environment on your own computer or server.
YOLOv8 / YOLO11 not only support object detection, but also yolov8-pose / YOLO11-pose for keypoint detection. In addition to the official human pose keypoints, you can also create your own keypoint dataset to train detection for specific objects and their keypoints.
Since YOLOv8 and YOLO11 mainly differ in their internal network structure, while preprocessing and postprocessing remain the same, the training and conversion steps for YOLOv8 and YOLO11 are identical. The only difference is the output node names.
Prerequisites
This article explains how to perform custom training, but assumes you already have some basic knowledge. If not, please learn the following first:
- This article does not explain how to install the training environment. Please search for and install a PyTorch training environment yourself.
- This article does not explain basic machine learning concepts or Linux fundamentals.
- The environment described in this article is based on a Linux desktop system. For Windows, please use a WSL2 environment, which supports X11. Please search for related information yourself.
Workflow and Goal of This Article
This is a workflow that requires zero algorithm background. As long as you know how to use Docker and how to annotate data, you can get your custom YOLO model running perfectly on MaixCAM/MaixCAM2 within 12 hours after receiving the device.
To use our model in MaixPy (MaixCAM), the following process is required:
- Set up the training environment. This article skips that part; please search for how to set up a PyTorch training environment.
- Clone the YOLO11/YOLOv8/YOLO26 source code locally.
- Prepare the dataset and convert it into the format required by the YOLO11 / YOLOv8 / YOLO26 project.
- Train the model and obtain an
onnxmodel file, which is also the final output of this article. - Convert the
onnxmodel into aMUDfile supported by MaixPy. This process is described in detail in the model conversion articles: - Use MaixPy to load and run the model.
Install Docker
Refer to the official Docker installation documentation for installation.
For example:
# Install basic software dependencies required by docker
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
# Add official repository
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# Install docker
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
Next, install the environment for exporting ONNX nodes.
Where to Find Datasets for Training
Prepare the Model Conversion Environment
Please reserve 100 GB of disk space for Docker, otherwise the conversion process may fail.
Note: Different versions of ultralytics export different nodes from the pt model file. Changing the version arbitrarily may cause the postprocessing code to mismatch the model outputs, making the model unusable. Therefore, please strictly use the version specified in the Dockerfile for exporting.
Create the ONNX Export Environment
# Build based on Python 3.10 slim image
FROM python:3.10-slim
# Set system and Python environment variables
ENV DEBIAN_FRONTEND=noninteractive \
PIP_NO_CACHE_DIR=1 \
PYTHONUNBUFFERED=1 \
MPLCONFIGDIR=/tmp/matplotlib
# Set container working directory to /app
WORKDIR /app
# Update apt source, install system dependencies and clean cache to reduce image size
RUN apt-get update && apt-get install -y --no-install-recommends \
git \
wget \
curl \
libglib2.0-0 \
libsm6 \
libxrender1 \
libxext6 \
libgl1 \
&& rm -rf /var/lib/apt/lists/*
# Upgrade pip and install CPU version of PyTorch related libraries
RUN pip install --upgrade pip && \
pip install \
torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/cpu
# Install specified version of ultralytics framework and dependencies
RUN pip install \
ultralytics==8.3.240 \
ultralytics-thop==2.0.18
# Clone YOLOv5 source code and install project requirements
RUN git clone https://github.com/ultralytics/yolov5.git && \
pip install -r /app/yolov5/requirements.txt
# Run environment inspection check
RUN yolo checks
# Switch working directory to /workspace
WORKDIR /workspace
# Default startup command for container is bash shell
CMD ["/bin/bash"]
Create a new
Dockerfilein an empty folder, then rundocker build -t onnx-export .to build the image.
Note: TheDockerfilefile has no extension.
Reference Articles
Since this is a fairly general workflow, this article only provides an overview. For details, please refer to the official YOLO26 / YOLO11 / YOLOv8 code and documentation (recommended), and search for related training tutorials. The final goal is to export an ONNX file.
If you find any good articles worth recommending, feel free to update this document and submit a PR.
Export the ONNX Model
Run the Docker environment:
docker run -it --rm -v ./:/workspace -w /workspace --network=host onnx-export:latest
For
yolov8n/yolo11n/yolo26, use theyolocommand line to export:
yolo export model=./yolo11n.pt format=onnx
Please replace./yolo11n.ptwith your own trained pt file.For
yolov5s(the model used by MaixHub online training), use:
python /app/yolov5/export.py --weights ./yolov5s.pt --include onnx --img 640 480
Please replace./yolov5s.ptwith your own trained pt file.
Here, the input resolution is specified again. The model was trained with 640x640, but we redefine the resolution to improve runtime speed. We use 640x480 here because its aspect ratio is closer to the MaixCAM2 screen, making display more convenient. For MaixCAM, you can use 320x224. You can choose the resolution according to your needs.
Convert to a Model and MUD File Supported by MaixCAM
MaixPy/MaixCDK currently support YOLO26 / YOLOv8 / YOLO11 detection, as well as YOLOv8-pose / YOLO11-pose keypoint detection, YOLOv8-seg / YOLO11-seg segmentation, and YOLOv8-obb / YOLO11-obb rotated bounding box detection (2026.2.4).
Output Node Selection
Pay attention to selecting the correct output nodes (note that your model values may not be exactly the same; refer to the figures below and find the corresponding nodes):
For YOLO11 / YOLOv8, MaixPy supports two output node selection schemes, and you can choose according to the hardware platform.
After determining the output nodes, you need to trim the ONNX model. For details, see [ONNX Model Node Trimming Tutorial].
| Model and Features | Option 1 | Option 2 |
|---|---|---|
| Applicable Devices | MaixCAM2 (recommended) MaixCAM (slightly slower than Option 2) |
MaixCAM (recommended) |
| Features | More computation is handled by CPU postprocessing, making quantization less likely to fail; speed is slightly slower than Option 2 | More computation is handled by the NPU and participates in quantization |
| Notes | None | Quantization fails on MaixCAM2 in actual tests |
| Detection YOLOv5s | /model.24/m.0/Conv_output_0/model.24/m.1/Conv_output_0/model.24/m.2/Conv_output_0 |
Same as MaixCAM2 |
| Detection YOLOv8 | /model.22/Concat_1_output_0/model.22/Concat_2_output_0/model.22/Concat_3_output_0 |
/model.22/dfl/conv/Conv_output_0/model.22/Sigmoid_output_0 |
| Detection YOLO11 | /model.23/Concat_output_0/model.23/Concat_1_output_0/model.23/Concat_2_output_0 |
/model.23/dfl/conv/Conv_output_0/model.23/Sigmoid_output_0 |
| Keypoints YOLOv8-pose | /model.22/Concat_1_output_0/model.22/Concat_2_output_0/model.22/Concat_3_output_0/model.22/Concat_output_0 |
/model.22/dfl/conv/Conv_output_0/model.22/Sigmoid_output_0/model.22/Concat_output_0 |
| Keypoints YOLO11-pose | /model.23/Concat_1_output_0/model.23/Concat_2_output_0/model.23/Concat_3_output_0/model.23/Concat_output_0 |
/model.23/dfl/conv/Conv_output_0/model.23/Sigmoid_output_0/model.23/Concat_output_0 |
| Segmentation YOLOv8-seg | /model.22/Concat_1_output_0/model.22/Concat_2_output_0/model.22/Concat_3_output_0/model.22/Concat_output_0output1 |
/model.22/dfl/conv/Conv_output_0/model.22/Sigmoid_output_0/model.22/Concat_output_0output1 |
| Segmentation YOLO11-seg | /model.23/Concat_1_output_0/model.23/Concat_2_output_0/model.23/Concat_3_output_0/model.23/Concat_output_0output1 |
/model.23/dfl/conv/Conv_output_0/model.23/Sigmoid_output_0/model.23/Concat_output_0output1 |
| Rotated Box YOLOv8-obb | /model.22/Concat_1_output_0/model.22/Concat_2_output_0/model.22/Concat_3_output_0/model.22/Concat_output_0 |
/model.22/dfl/conv/Conv_output_0/model.22/Sigmoid_1_output_0/model.22/Sigmoid_output_0 |
| Rotated Box YOLO11-obb | /model.23/Concat_1_output_0/model.23/Concat_2_output_0/model.23/Concat_3_output_0/model.23/Concat_output_0 |
/model.23/dfl/conv/Conv_output_0/model.23/Sigmoid_1_output_0/model.23/Sigmoid_output_0 |
| Detection YOLO26 | /model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0 /model.23/one2one_cv2.1/one2one_cv2.1.2/Conv_output_0 /model.23/one2one_cv2.2/one2one_cv2.2.2/Conv_output_0 /model.23/one2one_cv3.0/one2one_cv3.0.2/Conv_output_0 /model.23/one2one_cv3.1/one2one_cv3.1.2/Conv_output_0 /model.23/one2one_cv3.2/one2one_cv3.2.2/Conv_output_0 |
Same as MaixCAM2 |
| YOLOv8/YOLO11 detection output node diagram | 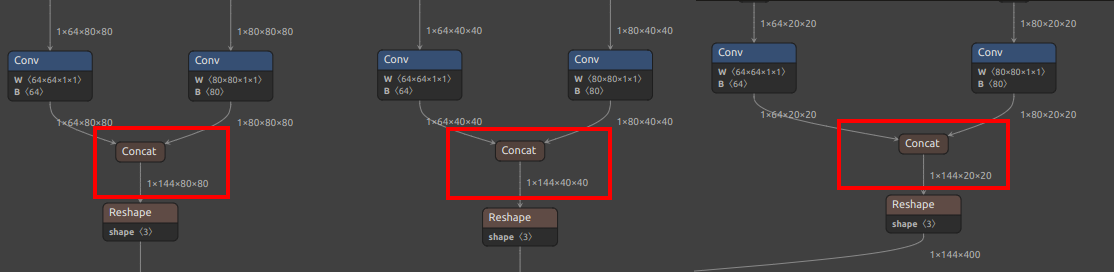 |
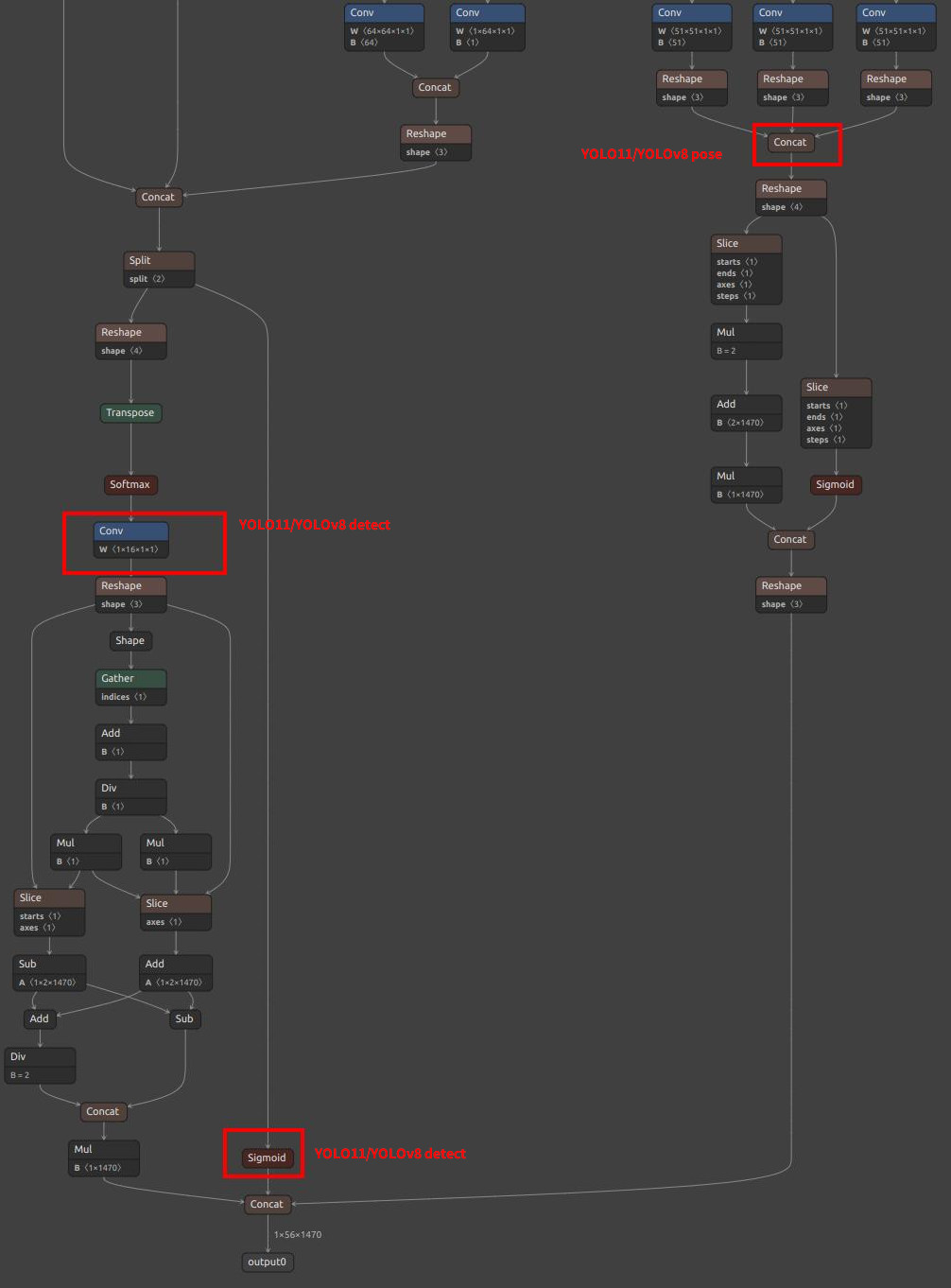 |
| Extra output nodes for YOLOv8/YOLO11 pose | 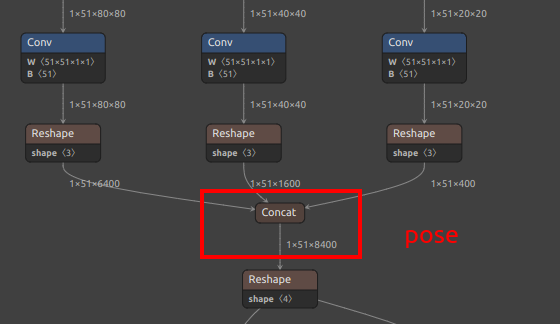 |
See the pose branch in the figure above |
| Extra output nodes for YOLOv8/YOLO11 seg | 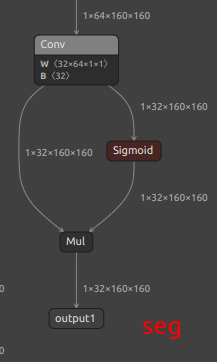 |
|
| Extra output nodes for YOLOv8/YOLO11 OBB | 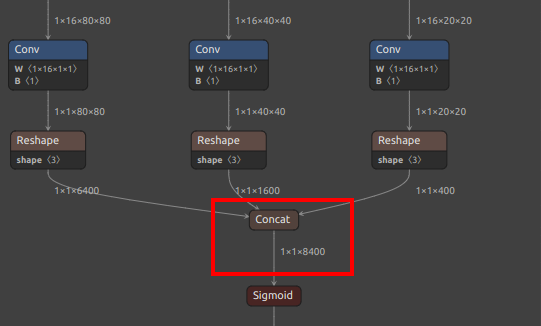 |
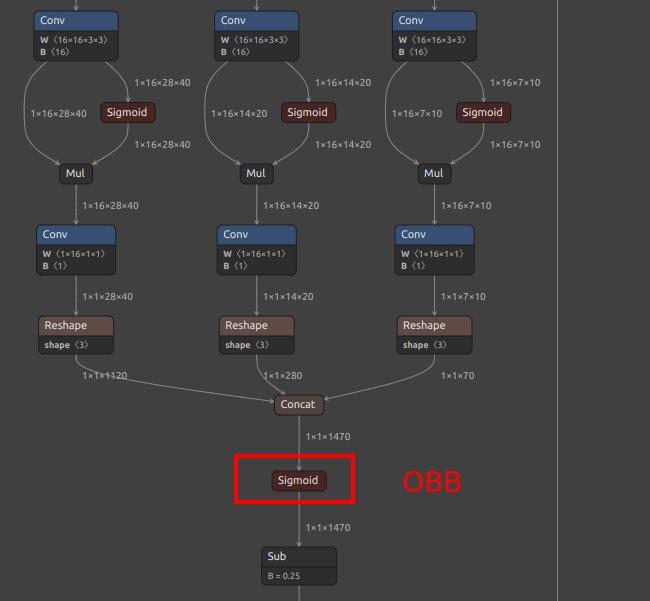 |
| Detection YOLO26 output node diagram | 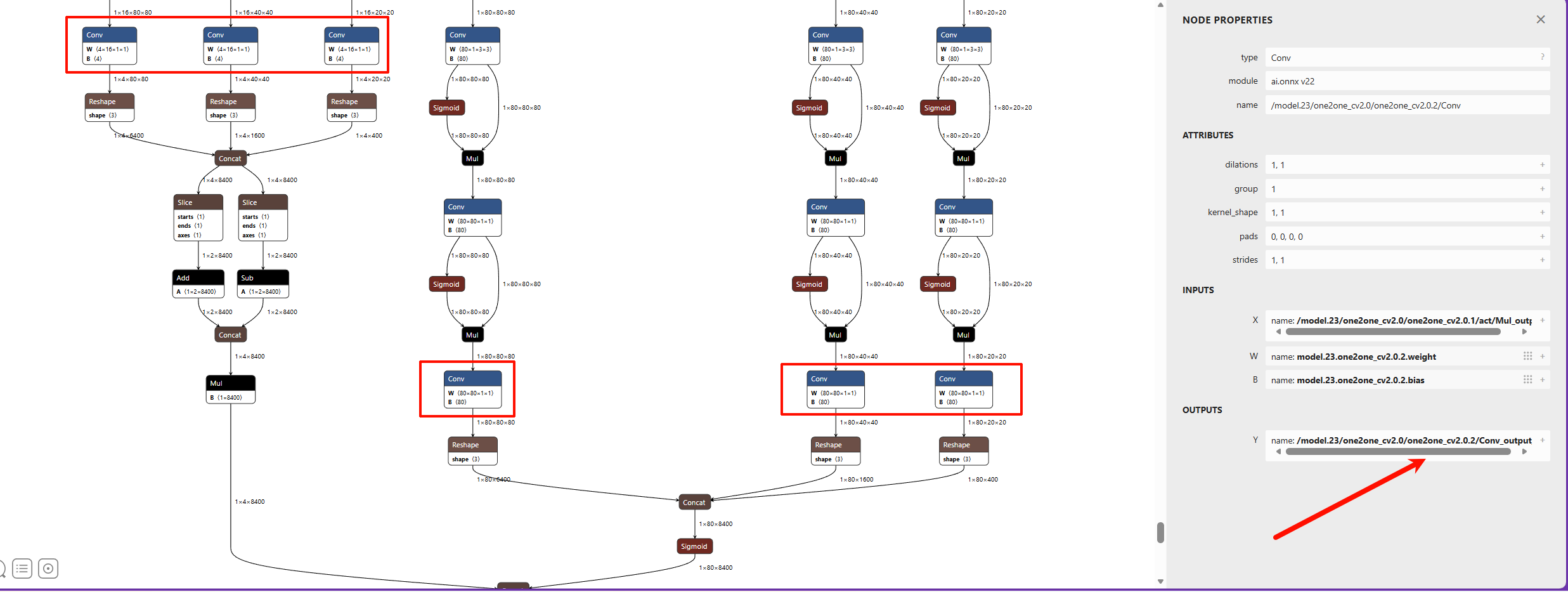 |
Same as MaixCAM2 |
Tutorial for Converting to NPU-Specific Model Files
Follow MaixCAM Model Conversion and MaixCAM2 Model Conversion to convert the model.
Modify the MUD File
For object detection, the MUD file is as follows (model_type should be changed to yolo11 for YOLO11 and to yolo26 for YOLO26):
MaixCAM/MaixCAM-Pro:
[basic]
type = cvimodel
model = yolov8n.cvimodel
[extra]
model_type = yolov8
input_type = rgb
mean = 0, 0, 0
scale = 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
labels = person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush
MaixCAM2:
[basic]
type = axmodel
model_npu = yolo11n_640x480_npu.axmodel
model_vnpu = yolo11n_640x480_vnpu.axmodel
[extra]
model_type = yolo11
type=detector
input_type = rgb
labels = person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush
input_cache = true
output_cache = true
input_cache_flush = false
output_cache_inval = true
mean = 0,0,0
scale = 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
Replace labels with the classes you trained on.
For keypoint detection (yolov8-pose), change type=pose.
For segmentation (yolov8-seg), change type=seg.
For oriented bounding boxes (yolov8-obb), change type=obb.
Upload and Share on MaixHub
Go to the MaixHub Model Zoo to upload and share your model. It is recommended to provide several resolutions for others to choose from.
